J'ai automatisé la publication sur mon blog depuis Google Doc avec n8n
Comment j'ai automatisé la publication d'un blog Next.js depuis Google Docs avec n8n, Cloudflare R2 et Coolify. Choix techniques et pièges rencontrés.
- J'ai d'abord développé un CMS custom (Next.js / NestJS / PostgreSQL), puis je l'ai abandonné : la correction orthographique de Google Docs est imbattable pour rédiger.
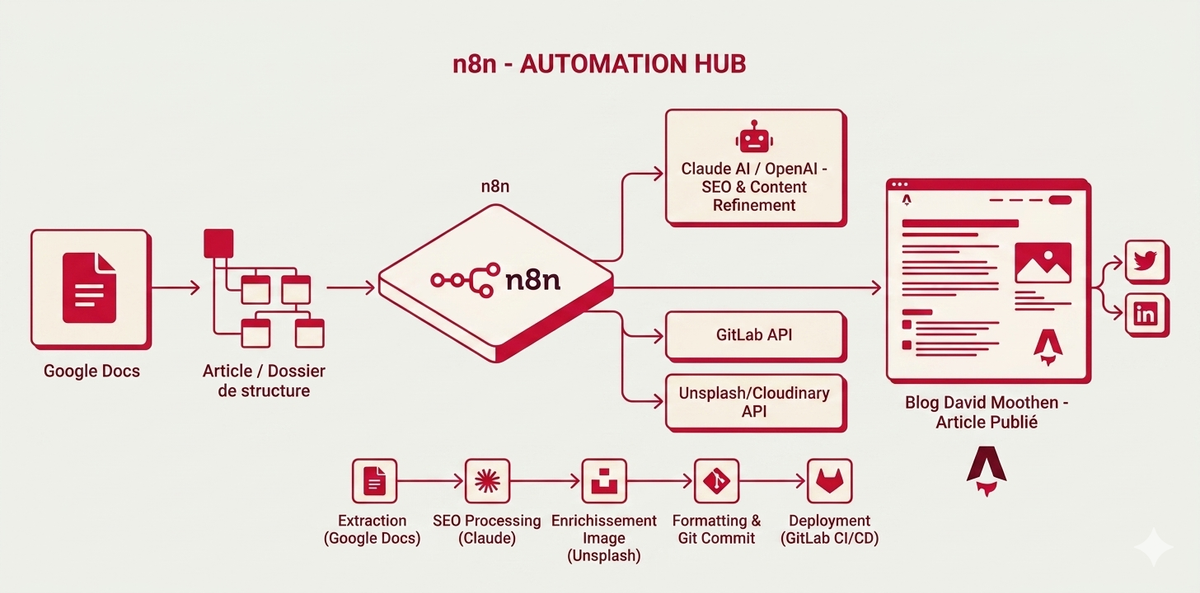
- Google Docs devient la source de vérité. Un pipeline n8n convertit les Docs en Markdown, nettoie l'export (regex), héberge les images sur Cloudflare R2 et committe dans le repo GitHub du blog.
- Le blog Next.js est déployé via Coolify sur un VPS Hetzner, un seul commit par exécution grâce à l'API GitHub GraphQL.
- Pipeline monté en environ 3 jours avec l'aide de Claude.
- Limites connues : suppression d'articles non détectée, ré-upload systématique des images, perte de qualité des images, unicité du slug non garantie, pas de mémoire d'exécution.
J'ai mis quelques jours à construire un pipeline qui transforme mes documents Google Docs en articles publiés sur ce blog. Un processus automatisé pour me concentrer entièrement sur la rédaction de mes articles.
Voici comment j'ai créé ce pipeline avec n8n, Next.js, Cloudflare R2 et Coolify, l'évolution du projet de l'idée d'origine à la version actuelle, et les contraintes techniques que je n'avais pas vu venir.
Pourquoi je n'ai pas utilisé WordPress (ni de CMS classique)
Il existe de nombreuses solutions clés en main pour déployer un blog en quelques minutes, que ce soit des CMS comme Wordpress, Drupal, Joomla ou des solutions auto-hébergées comme Wix ou Webflow pour ne citer que les plus connus. J'ai eu l'occasion d'en utiliser certains avec le temps, et je pense que ces solutions peuvent parfaitement convenir à une large majorité de projets, compte tenu des contraintes qu'elles imposent.
Mais personnellement en tant que développeur, quand j'utilise ces frameworks, la frustration l'emporte généralement sur la facilité. Je n'arrive jamais vraiment à obtenir le résultat souhaité et je n'ai pas forcément ni le temps, ni même l'envie de faire une formation sur le sujet. J'en parle brièvement dans mon article précédent, dans lequel j'explique pourquoi j'ai développé une application pour créer mon CV plutôt que d'utiliser Word.
Je décide donc de développer mon propre blog, avec l'aide de Claude Code.
Premier essai : le CMS custom
Pourquoi je suis parti sur Next.js + NestJS + PostgreSQL
Ayant l'habitude de développer des applications web fullstack, je suis d'abord parti sur l'idée d'une application web complète, avec un dashboard d'administration pour éditer mes articles, le tout reposant sur ma stack de prédilection.
Je travaille actuellement sur un autre projet ayant une base similaire, j'ai donc repris celle-ci pour ne pas démarrer de zéro.
Je vais jusqu'au bout du projet et les premiers tests sont concluants. L'édition et la publication fonctionnent bien, concrètement je peux commencer à utiliser mon CMS.
Et c'est en commençant à rédiger mon premier article que j'ai vu apparaître un problème.
Google Docs reste imbattable pour la rédaction
J'avais déjà commencé la rédaction de mon premier article dans Google Docs en parallèle. Je reprends donc l'écriture de mon article dans le dashboard d'administration de mon CMS custom. Mais je remarque que la correction orthographique n'est pas aussi efficace que dans Google Docs.
Comme je débute dans la rédaction d'articles (celui-ci n'est que le deuxième), je fais beaucoup d'erreurs à la saisie, bien plus que je ne l'aurais pensé ! J'espère m'améliorer avec le temps, mais en attendant, j'ai besoin d'avoir une assistance efficace sur ce sujet.
Je fais quelques recherches pour essayer d'améliorer la correction orthographique sans faire de gros changements. Malheureusement, à moins d'utiliser des solutions payantes ou des plugins dans le navigateur qui ne gèrent pas le multi-langue, je ne trouve rien d'intéressant.
Et l'idée de rédiger mes articles dans Google Docs, puis de les "copier-coller" dans mon CMS me paraît compliqué à gérer sur le long terme. Je dois recommencer à chaque fois que je crée ou met à jour un article. Et je n'ai même pas encore abordé la gestion des images, etc.
Bref, tout ça manque de fluidité.
Google Docs comme source de vérité
Pour bénéficier de la correction orthographique de Google Docs, je décide d'abandonner l'approche CMS au profit d'une approche automatisée. Google Docs devient la source de vérité. Tout ajout, modification ou suppression d'un article devra se répercuter sur le site, et idéalement sans aucune action de ma part.
Parmi les solutions d'automatisation existantes, je choisis arbitrairement n8n tout simplement parce que j'en avais déjà entendu parler. Et maintenant que j'ai un cas concret d'utilisation, je vais pouvoir commencer mes expérimentations. Je lance une conversation avec Claude pour valider mon plan d'action :

Voilà l'idée dans les grandes lignes : Google Docs pour rédiger mes articles, un blog développé avec Next.js, et n8n pour faire lien entre les deux. Passons à la pratique.
Le blog Next.js : design et conventions
Je veux développer un blog relativement simple : une landing avec la liste des derniers articles parus, une autre pour voir tous les articles, une dernière pour les visualiser et il sera développé avec Next.js, par contre je n'ai pas encore pensé au design. Je commence donc ma réflexion.
Un prototype en quelques heures avec Claude Code
Pour trouver de l'inspiration, je demande à Claude de chercher 5 blogs de développeurs ayant un profil similaire au mien. Parmi les résultats, il y en a un en particulier qui me tape dans l'œil : celui de Tania Rascia. J'aime beaucoup son style personnel et minimaliste.
Je demande à Claude Code de me créer un blog Next.js avec les contraintes suivantes :
- une liste des thèmes qui seront abordés, la technologie, l'entrepreneuriat et le développement personnel
- une landing
- 3 articles sur chacun des thèmes
- un design sobre et minimaliste
- prévoir le multilingue (même si pour l'instant tout est en français)
Le premier jet ressemblait à 90% au site que vous voyez actuellement. J'ai continué à affiner le résultat pour personnaliser l'affichage de la navbar, du footer, choisir la couleur principale etc.
Le blog est maintenant prêt à accueillir mon premier article.
Le format Markdown (.md)
Pour afficher un article dans le blog au format html, nous allons convertir nos Google Docs au format Markdown. C'est un format qui est grandement utilisé pour rédiger du contenu au format texte, notamment des articles de blog. Sa syntaxe simplifiée se convertit naturellement en html. Il y a notamment une page dédiée dans la documentation de Next.js sur l'utilisation du markdown.
Les articles seront donc stockés dans le code source au format markdown et seront convertis en html grâce à la librairie next-mdx-remote.
Voici quelques liens pour en savoir plus sur le format Markdown :
- https://www.nexa.fr/blog/quest-ce-que-le-langage-de-programmation-markdown
- https://medium.com/@wetrocloud/why-markdown-is-the-best-format-for-llms-aa0514a409a7
La convention frontmatter
Au début de chaque document, nous allons stocker les métadonnées d'un article (les données invisibles qui servent à décrire le document comme son identifiant, la catégorie à laquelle l'article appartient, son slug etc. Ensuite vient le contenu de l'article lui-même, le texte que vous êtes actuellement en train de lire.

Je me sers également du frontmatter, pour décider d'un certain nombre de conventions :
- Un article sera stocké dans un fichier "
content/locale/id-slug.mdx" - Il sera accessible sur le blog via l'url "
/locale/articles/slug" - l'id sera compris entre 0001 et 9999 (ça sera problématique si j'arrive à écrire 10 000 articles, ça me laisse de la marge !)
- le boolean index contrôle le référencement ou non de l'article
Si vous voulez en savoir plus sur le frontmatter : https://www.markdownlang.com/fr/advanced/frontmatter.html
Avant de mettre en place l'automatisation, je demande à Claude de lire le Google Doc de mon premier article et de l'insérer dans le code source au format markdown. En faisant cela, je m'assure que tout marche correctement et que mon plan est valide.
Arrivé ici, le blog est en ligne. Certes il ne contient qu'un seul article pour le moment, mais ça devrait changer rapidement, notamment grâce à l'automatisation.
Pour tester le projet, je demande à Claude de me rédiger un article test. Il servira à tester le workflow. Je choisis comme sujet un jeu que j'ai relancé il y a quelques jours : FTL : Faster Than Light. Je copie colle l'article dans un Google Doc et je mets à disposition l'export au format pdf. Dedans, vous verrez à quoi ressemble un article fini, le point de départ de l'automatisation. Le résultat est visible ici.
Le blog est prêt à accueillir nos articles, il est temps de l'alimenter.
Construction du pipeline n8n
Dans cette partie, nous allons voir comment automatiser l'ajout des articles dans le blog. Nous allons pour cela nous servir de l'article test pour vérifier que toutes les étapes fonctionnent bien.
Le serveur (Coolify + Hetzner)
Pour pouvoir commencer, il nous faut d'abord un serveur. Il existe deux façons d'obtenir ce serveur :
- Utiliser la version en ligne (Cloud)
- Déployer son propre serveur (Self-Hosted)
Je ne vais pas rentrer dans le détail ici, ce n'est pas le but de l'article. Si cela vous intéresse, voici un article intéressant sur le sujet: https://dev.to/ciphernutz/n8n-self-hosted-vs-n8n-cloud-which-one-should-you-choose-in-2025-1653
J'utilise déjà un VPS chez Hetzner sur lequel j'ai installé Coolify. J'y ai déployé différents sites, notamment celui de ma société Jinious, ainsi que le présent blog. Je vais donc privilégier la seconde approche.
Le concept de n8n en deux minutes
Le concept est relativement simple à comprendre : il va falloir configurer et connecter des nodes pour former l'automatisation.
Les données produites à la sortie d'un node (output) sont récupérées à l'entrée du node suivant (input).
Le premier node déclenche l'automatisation, il peut aussi bien s'agir d'un trigger manuel (l'automatisation se déclenche quand je clique dessus) que des événements spécifiques, comme la réception d'un email sur son compte Gmail.
Enfin, chaque node est responsable d'une tâche spécifique (comme nous allons le voir après), ce qui oblige à découper le processus en plusieurs sous-parties
C'est un très rapide résumé du fonctionnement, je vous mets un lien ici si vous voulez en savoir plus sur le fonctionnement et sur des exemples de use-cases : https://www.hyperstack.studio/blog/guide-n8n-2026
Avec l'aide de Claude, je parviens à prendre n8n en main et fini par compléter le pipeline.
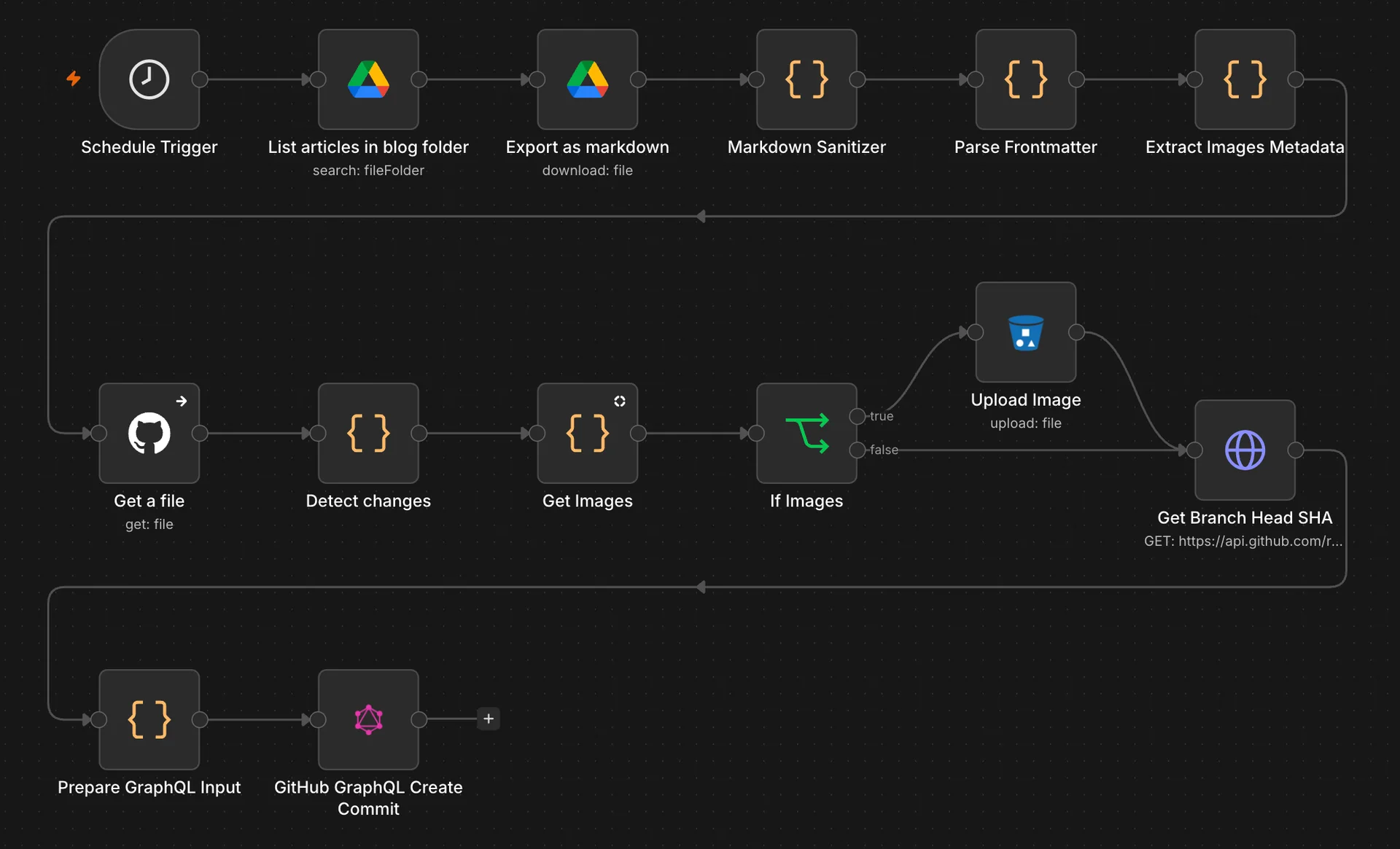
Aurait-on pu tout déléguer à un LLM ?
Comme on peut le voir, le pipeline contient beaucoup de nodes, bien plus que ce que j'avais imaginé au départ. Il y a notamment 6 nodes de code javascript (ceux avec des accolades oranges). Est-ce qu'on aurait pu construire un pipeline plus court ?
Dans l'ensemble des nodes disponibles dans n8n, il y a une catégorie "IA" dans laquelle se trouvent des nodes permettant d'interagir avec un LLM. Il suffit donc de choisir le bon node, de configurer sa clé API et d'écrire son prompt. Tout le travail d'automatisation (conversion au format markdown, nettoyage, gestion des images, commit) serait alors délégué au LLM. C'est finalement comme ça que j'ai intégré mon premier article, sauf que j'ai demandé à Claude directement plutôt que de passer par n8n.
Je n'ai pas choisi cette approche ici principalement pour des raisons de coûts. Lorsque l'on utilise un LLM avec sa clé API, on est facturé à la requête. Et la facture peut vite augmenter ! J'ai préféré faire autrement moyennant quelques lignes de code.
Le pipeline fonctionne bien globalement, mais j'ai dû faire quelques concessions au passage.
Les pièges que je n'avais pas anticipés
Pendant la mise en place de l'automatisation, j'ai dû prendre en compte un certain nombre de difficultés qui sont apparues en cours de route.
L'export markdown de Google Doc n'est pas exploitable directement par mon blog
Claude avait converti mon premier article de façon à ce qu'il soit directement intégrable dans le code source du blog. En revanche, le markdown exporté depuis Google Doc n'est pas compatible directement. Il a donc été nécessaire de rajouter un node supplémentaire pour nettoyer le markdown afin de pouvoir l'intégrer dans le code source, au moyen d'expressions régulières. Merci à Claude pour les Regex !
// Mode : Run Once for Each Item
const buffer = await this.helpers.getBinaryDataBuffer($itemIndex, 'data');
// Note : on passe de `const` à `let` car on va modifier le contenu
let content = buffer.toString('utf8');
// === Regex 1/N : déséchapper les délimiteurs frontmatter ===
// Google exporte `\---` au lieu de `---` (échappement défensif).
// Sans correction, le YAML parser ne reconnaît pas le frontmatter.
content = content.replace(/^\\---\s*$/gm, '---');
// === Regex 2/N : déséchapper les crochets autour des tags ===
// Google échappe les `[` et `]` du frontmatter en `\[` et `\]`,
// ce qui casse le parsing YAML de l'array.
content = content.replace(/^tags:\s*\\\[(.*?)\\\]/m, 'tags: [$1]');
// === Regex 3/N : convertir `**bool**` en bool YAML correct ===
// Google exporte `draft: **false**` quand l'auteur a mis le `false` en gras.
// YAML parse alors comme string truthy au lieu de booléen → bug silencieux.
content = content.replace(/^(\w+):\s*\*\*(true|false)\*\*\s*$/gm, '$1: $2');
// === Regex 4/N : retirer le bold redondant dans les headings ===
// Google exporte `## **Title**` parce que le style "Heading 2" inclut le bold.
// Nos headings sont déjà stylés bold via CSS dans .prose, donc inutile.
content = content.replace(/^(#{1,6})\s+\*\*(.+?)\*\*\s*$/gm, '$1 $2');
// === Regex 5/N : normaliser les puces de liste `*` → `-` ===
// Google utilise `*` pour les bullets, on préfère `-` (purement stylistique
// mais évite les ambiguïtés avec `**bold**`).
content = content.replace(/^(\s*)\*\s/gm, '$1- ');
// === Regex 6/N : forcer le quoting de l'id (4 chiffres) ===
// Si l'auteur écrit `id: 0001` sans quotes, YAML parse en number `1`
// (leading zeros perdus). Notre validation typeof === "string" throw.
// On force toujours le quoting pour éviter ce piège.
content = content.replace(/^id:\s*(\d{4})\s*$/m, 'id: "$1"');
// === Regex 7/N : normaliser les smart quotes en straight quotes ===
// Legacy : pour les articles écrits avant la désactivation des substitutions
// Google. Les guillemets " " (U+201C/D) et apostrophes ' ' (U+2018/9)
// sont remplacés par leurs versions ASCII droites.
// Sécurité : sans ça, `locale: "fr"` ne matche pas la whitelist YAML.
content = content
.replace(/[\u201C\u201D]/g, '"')
.replace(/[\u2018\u2019]/g, "'");
// === Regex 8/N : déséchapper les caractères de ponctuation du corps ===
// Google échappe défensivement +, =, ~, ., (, ), [, ], !, <, >
// même quand ce n'est pas nécessaire. On les remet propres.
// Safe : on ne touche pas aux backslashes suivis de \n, \t, \r, \\, etc.
content = content.replace(/\\([+=~.()\[\]!<>])/g, '$1');
// === Regex 9/N : retirer les trailing whitespaces ===
// Google ajoute 2 espaces en fin de chaque ligne (syntaxe Markdown pour <br>).
// Inutile dans 99% des cas, et pollue le source.
content = content.replace(/[ \t]+$/gm, '');
// Cleanup : compresse les lignes vides multiples qui peuvent rester
// après suppression des images (>= 3 \n consécutifs → max 2)
content = content.replace(/\n{3,}/g, '\n\n');
return {
json: {
// Métadonnées du fichier source (utiles pour debug et logs)
sourceFileId: $input.item.json.id,
sourceFileName: $input.item.json.name,
// Le contenu complet sanitizé — c'est LA donnée principale
// qui va être consommée par les nodes suivants (parsing YAML, commit GitHub, etc.)
content: content,
// Longueur — utile pour monitoring et alerting si jamais
// un sanitizer foire et produit un fichier vide ou anormal
length: content.length,
},
};
Gérer efficacement les images
C'est un point auquel je n'avais volontairement pas réfléchi en amont, je voulais d'abord créer une automatisation capable de gérer des articles sans images dans un premier temps. Pour le stockage j'ai choisi Cloudflare R2 car c'est le plus avantageux financièrement. Ensuite il a fallu rajouter 4 nodes supplémentaires pour gérer les images :
- Extract Images Metadata : lis le contenu du texte et remplace les images par leur url finale (on peut la déterminer grâce aux conventions qu'on a mises en place dans le frontmatter)
- Get Images : récupère l'ensemble des images à sauvegarder dans R2 (sur l'ensemble des articles)
- If Images : node conditionnel qui vérifie qu'il y a bien des images à uploader
- Upload Image : stocke les images dans R2.
Et l'upload de ces images, ainsi que la mise à jour du code source ne doit se faire que s'il y a eu des modifications dans le Google Drive. On ajoute donc un cinquième node pour déterminer s'il y a des ajouts de nouveaux articles ou des modifications d'articles existants.
Utiliser Github GraphQL API
Un autre cas auquel je n'avais pas pensé également : les nodes github "Edit a file" et "Create a file" produisent un commit chacun. Donc si j'ajoute un article et en modifie deux, cela produit trois commits, et donc trois déploiements sur le serveur ! Pour ne produire qu'un seul commit pour tous les changements, j'ai dû avoir recours à la mutation createCommitOnBranch de l'api Github GraphQL API ce qui a généré trois nodes supplémentaires ("Get Branch Head SHA", "Prepare GraphQL Input" et "Github GraphQL Create Commit").
Ce qu'il reste à améliorer
L'automatisation telle que je l'ai créée est adaptée à mon utilisation personnelle et fonctionne correctement pour le moment. Il y a un certain nombre d'améliorations possibles, mais qui ne sont pas forcément urgentes.
Le pipeline ne détecte pas les articles supprimés
Il faudrait comparer la liste des fichiers markdown à celle des documents présents dans le Google Drive pour voir ceux qu'il manque et les retirer du code source. Dans mon cas, il est peu probable que cela arrive, et si ça devait arriver, je supprimerai directement le fichier du code source.
Les images sont toujours uploadées
Le pipeline n'upload les images d'un article que si celui-ci est nouveau ou bien a été mis à jour. Dans le second cas, il est probable que les images soient déjà présentes dans l'espace de stockage. Il pourrait être intéressant de faire cette vérification pour savoir si l'upload est nécessaire.
Les images perdent en qualité
Dans Google Docs, les images insérées sont directement converties en base64 avec une perte de qualité. C'est un fait connu dans le fonctionnement de Google Docs. Les images uploadées sur R2 sont donc aussi impactées. Il est probable que je finisse par gérer manuellement le stockage des images. En contrepartie, cela me permettrait de supprimer quatre nodes du pipeline.
Garantir l'unicité du slug
Il n'y a pas de vérification sur l'unicité des champs clés du frontmatter. Dans le cas où deux articles se retrouveraient avec le même slug, seul l'un d'entre eux serait visible en ligne. Cela reste gérable manuellement pour l'instant, mais c'est probablement quelque chose que je vais devoir corriger dans quelques mois.
L'automatisation lit l'ensemble des Google Docs
Avec le temps, les anciens articles ne devraient plus être modifiés, il est donc inutile d'aller les consulter car ils seront de toute façon exclus du pipeline par le node "Detect changes". Pour pallier ça, il faudrait ajouter une "mémoire" au pipeline, pour sauvegarder la date dernière exécution du workflow. On utiliserait alors cette date au tout début dans le node "List articles in blog folder" pour ne garder que les documents qui ont été ajoutés et modifiés depuis.
Bilan : 3 jours pour automatiser la publication
J'ai été capable de créer un système entièrement automatisé en quelques jours seulement avec l'aide de Claude. Je n'ai fait qu'effleurer la surface en matière d'automatisation, mais grâce à cette première expérience, je commence à comprendre la puissance de l'outil et ce qu'on peut faire avec. Même si avec le recul, il y a certains concepts que j'aurais trouvé assez difficile si je n'avais pas été un développeur. Quoi qu'il en soit, le blog est bien en ligne et je peux me concentrer sur la rédaction de mes articles sans avoir à me soucier de la publication.