Automatiser ses comptes rendus de RDV avec n8n, Mistral et Notion
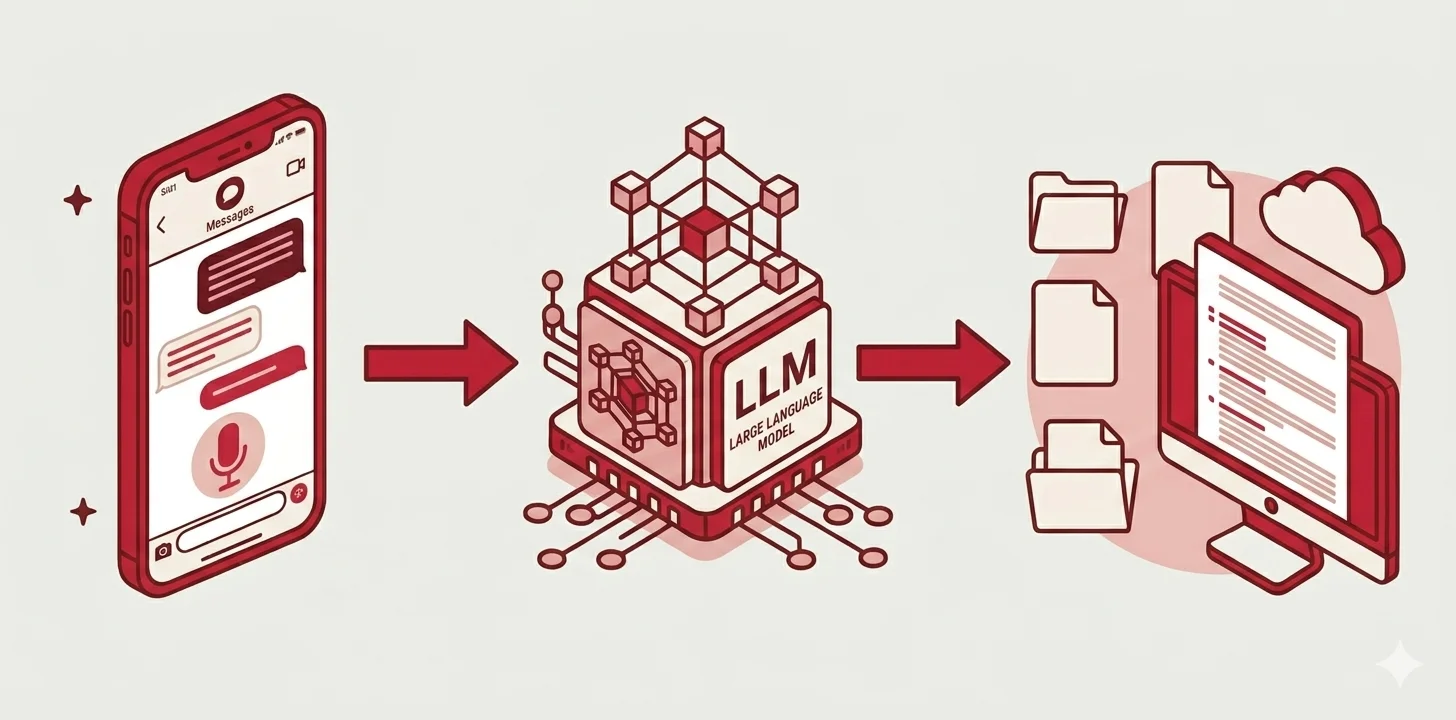
Retour d'expérience : comment j'ai automatisé la structuration de mes comptes rendus de RDV clients avec n8n, Telegram, Mistral AI et Notion, sans coder de CRM.
- Je dicte mon compte rendu de RDV en texte dans Telegram (saisie vocale, pas d'audio).
- Un workflow n8n envoie le message à Mistral Small, qui le restructure en JSON (résumé, points-clés, décisions, actions, points d'attention…).
- Le résultat est sauvegardé automatiquement comme entrée dans une base Notion.
- Résultat : un pipeline en 5 nodes, monté en quelques jours, sans développer de CRM.
- Limites connues : pas de gestion de l'unicité client ni de pièces jointes (→ 2ᵉ article à venir).
Suite à ma première expérience concluante sur l'automatisation du blog, j'ai voulu continuer à expérimenter le sujet de l'automatisation, mais cette fois dans le cadre de mon activité professionnelle.
Dans cet article, je vais vous expliquer comment j'ai automatisé la structuration de mes comptes rendus avec n8n, Telegram, Notion et Mistral AI.
Pourquoi automatiser ses comptes rendus client ?
Imaginez la situation suivante : vous préparez votre prochain rendez-vous avec votre client, pour lui faire votre proposition commerciale. Cela fait maintenant plusieurs semaines que vous échangez sur son projet, que ce soit en présentiel, en vision, par mail, messagerie, etc.
Le problème : une information éclatée sur trop de canaux
Pour préparer votre proposition, vous allez devoir réunir toutes les informations que vous avez récoltées au cours de vos échanges. Mais cela ne vous aura pas échappé : il existe beaucoup de moyens et d'outils différents pour communiquer, à tel point que retracer l'ensemble des échanges peut vite devenir un parcours du combattant ! Dans mon cas, j'ai des clients qui communiquent avec moi aussi bien par mails, whatsapp (textes et vocaux !), téléphone, slack, sans compter mes notes (manuscrites !) prises pendant nos échanges, aussi bien en ligne qu'en présentiel.
L'information est éclatée sur plusieurs canaux, et avant même d'avoir commencé votre travail de réflexion, vous perdez votre temps à réunir les informations !
Ma gestion actuelle de la prospection
En temps normal, je gère un client à la fois, parfois deux en même temps mais rarement plus. Je me contente d'un bloc-note, d'un Google Drive si j'ai besoin de stocker des documents, et éventuellement d'un outil supplémentaire comme Trello ou Notion, si le besoin s'en fait ressentir. C'est une gestion très simple, presque artisanale, mais qui a le mérite de fonctionner. Par contre, j'ai bien conscience que ce process est limité et qu'il risque de me poser des problèmes sur le long terme.
C'est pourquoi je souhaite commencer à mettre en place les bonnes pratiques et être plus rigoureux dans ma gestion dès maintenant, ne serait-ce que pour avoir un historique clair et facilement consultable.
Éviter le biais du développeur : CRM custom ou automatisation ?
Mon premier réflexe serait de commencer à réfléchir au développement d'un CRM custom. Mais comme on l'a vu dans mon précédent article sur l'automatisation du blog, j'avais fini par délaisser cette approche après avoir développé un MVP complet. Et j'écarte encore une fois l'idée d'utiliser un CRM payant à ce stade. L'idée ici est d'expérimenter, à moindre coût.
Ayant retenu la leçon, je commence cette fois ma réflexion sur la possibilité d'utiliser n8n pour créer une automatisation qui pourrait faire l'affaire.
Préparer le plan du pipeline n8n
Avant de nous lancer dans la création du pipeline, nous allons planifier notre approche afin de préparer le terrain. L'objectif est aussi de voir si on peut déjà déceler des problèmes de conception et y remédier en amont.
Le projet : dicter un compte rendu et le structurer automatiquement
Voici comment j'imagine les choses : je viens de terminer un rendez-vous avec un client potentiel qui m'a fait part de ses besoins. Je saisis mon smartphone et commence à dicter mon compte rendu :
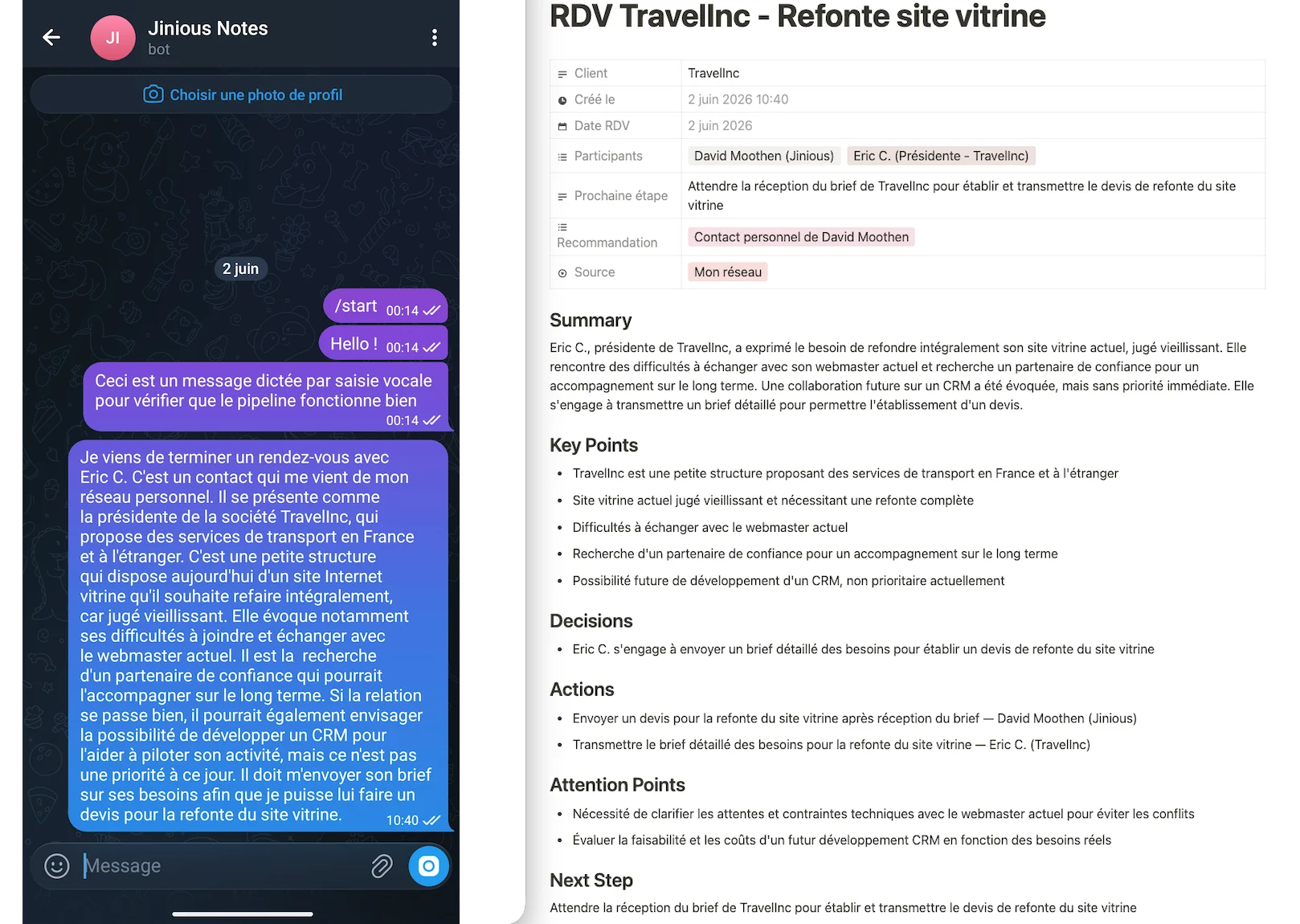
"Je viens de terminer un rendez-vous avec Eric C. C'est un contact qui me vient de mon réseau personnel. Il se présente comme le président de la société TravelInc, qui propose des services de transport en France et à l'étranger. C'est une petite structure qui dispose aujourd'hui d'un site Internet vitrine qu'il souhaite refaire intégralement, car jugé vieillissant. Il évoque notamment ses difficultés à joindre et échanger avec le webmaster actuel. Il est à la recherche d'un partenaire de confiance qui pourrait l'accompagner sur le long terme. Si la relation se passe bien, il pourrait également envisager la possibilité de développer un CRM pour l'aider à piloter son activité, mais ce n'est pas une priorité à ce jour. Il doit m'envoyer son brief sur ses besoins afin que je puisse lui faire un devis pour la refonte du site vitrine."
Important : j'utilise ici la saisie vocale pour dicter mon message et non un vocal. C'est donc bien un texte qui est envoyé et non un audio. Je vois deux avantages à ne pas envoyer un vocal (audio) directement :
- On peut relire le message et le corriger si besoin avant de l'envoyer. C'est particulièrement pratique pour des noms de famille par exemple.
- Ça sera plus simple de travailler avec du texte plutôt qu'un audio.
Le message est ensuite récupéré par un LLM. Il va analyser le texte puis le restituer sous forme d'un compte rendu détaillé que je pourrai ensuite consulter à ma guise.
Les outils
Je lance une conversation avec Claude pour réfléchir sur l'implémentation et valider mon idée. Je lui donne tous les détails dont il a besoin : le projet, le contexte, l'exemple ci-dessus, etc. Je lui laisse aussi le soin de me définir le format du compte rendu. À ce stade, l'objectif est d'avoir un pipeline fonctionnel. Je pourrais toujours faire des corrections sur le format ensuite.
Au bout de quelques prompts un schéma global commence à prendre forme. Le pipeline reposera sur trois nodes :
- Un déclencheur : une application de messagerie pour saisir et envoyer notre message.
- Un analyseur : un LLM qui va récupérer le message et le formater pour produire notre compte rendu.
- Un service de stockage : pour pouvoir sauvegarder et consulter nos comptes rendus quand je le souhaite.
Une petite anecdote pour terminer cette introduction : je voulais insérer à cet endroit un schéma du pipeline que je viens de décrire. J'ai demandé à Gemini de me générer l'image en question. Elle collait tellement bien au thème de l'article dans sa globalité que j'ai décidé d'en faire la bannière de l'article !
Maintenant que nous avons notre plan d'action, passons à la partie pratique.
Première version du pipeline : de Telegram à Notion
Nous avons déterminé dans la partie précédente les principaux nodes sur lesquels reposent notre pipeline. Je vais d'abord commencer par une version simplifiée.
Configurer le déclencheur Telegram
C'est le point d'entrée de notre pipeline, celui qui va déclencher le workflow. Je lance une petite recherche sur Google avec les termes "n8n message trigger". Le deuxième lien qui ressort pointe directement sur la documentation n8n et mentionne Telegram. Je parcours rapidement la page et je valide l'existence d'un node Telegram dans n8n qui se déclenche à la réception d'un message. Je trouve ensuite un excellent article qui explique comment configurer ce node. Quelques minutes plus tard, mon déclencheur est prêt.
Sauvegarder les comptes rendus dans Notion
Pour enregistrer les comptes rendus, j'ai choisi d'utiliser Notion. Je ne m'en suis jamais vraiment servi, mais j'avais déjà créé un compte car à l'époque, j'ai travaillé pour un client qui s'en servait régulièrement et qui souhaitait que je rejoigne son projet. Par contre je sais qu'il est possible de faire beaucoup de choses avec, notamment s'en servir comme une base de données.
J'ai utilisé Claude pour m'expliquer comment créer cette base de données. Voici son schéma :
| CHAMP | TYPE |
|---|---|
| Titre | Text |
| Client | Text |
| Date RDV | Date |
| Participants | Sélection multiple |
| Source | Sélectionner |
| Recommandation | Sélection multiple |
| Prochaine étape | Texte |
| Créé le | Date de création |
Je récupère l'id de la page pour configurer un node Notion - Append a block, que je connecte à mon déclencheur.
Tester la version simplifiée
Le pipeline est prêt, nous avons correctement configuré Telegram et Notion, il ne nous reste plus qu'à vérifier que tout fonctionne bien :
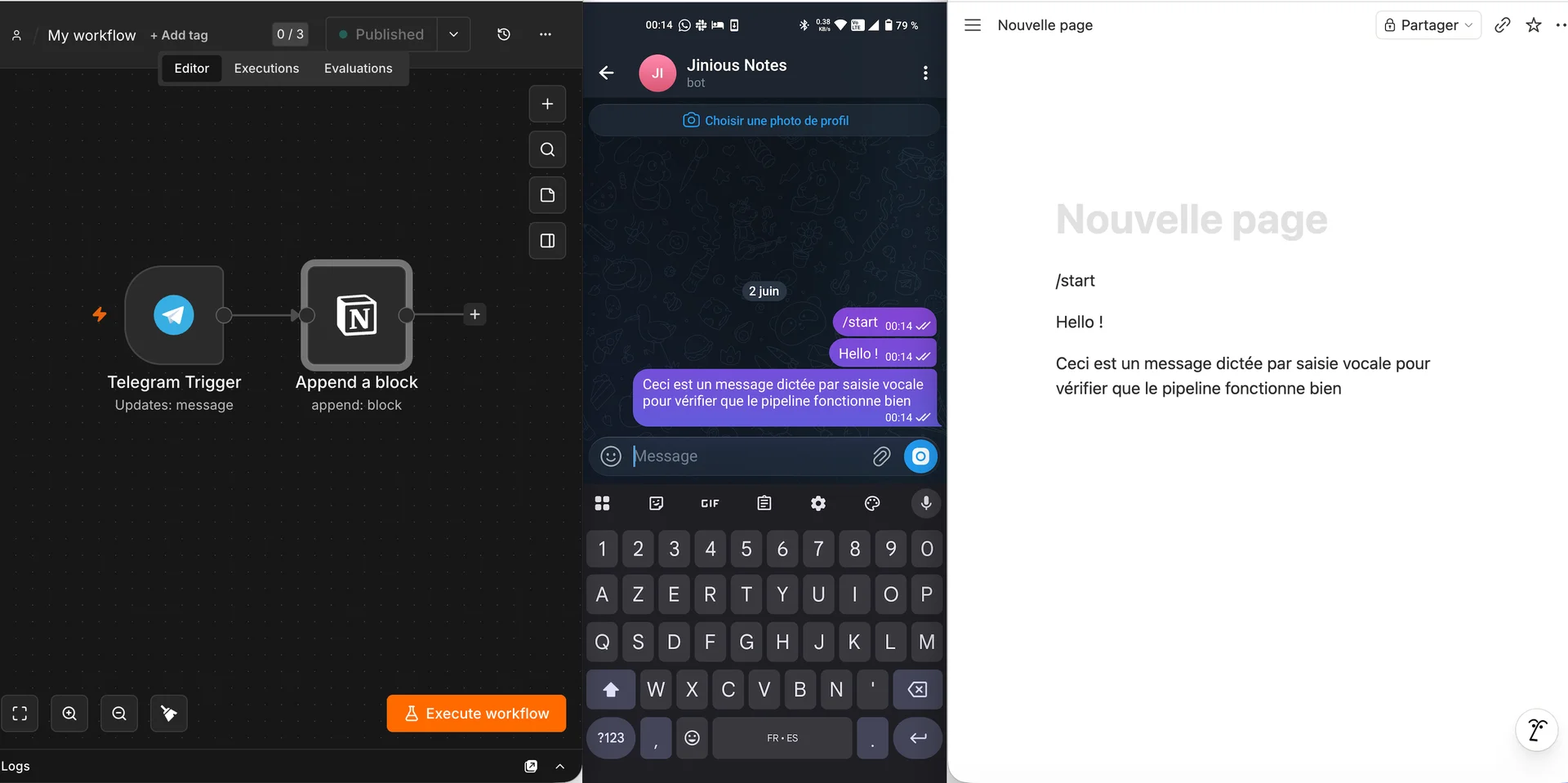
On peut maintenant passer à la version finale.
Mettre de l'intelligence (artificielle)
Maintenant que la base est prête, nous allons la faire évoluer pour répondre à notre besoin initial. Nous allons devoir apporter deux modifications à notre pipeline.
À quoi doit ressembler un bon compte rendu ?
Avant de commencer, il nous faut d'abord savoir à quoi va ressembler un compte rendu. Pour l'instant nous avons quelques champs dans une base de données, mais il nous manque l'essentiel : un résumé, les points-clés, les décisions prises, les points d'attentions, etc. L'objectif du LLM, que nous allons intégrer prochainement, sera de lire le message et de produire ces informations, puis de les envoyer à Notion pour les sauvegarder. Après quelques échanges avec Claude sur le sujet, l'output du node LLM aura le format suivant :
{
title: string;
client: string;
meeting_date: string;
participants: string[];
summary: string;
key_points: string[];
decisions: string[];
actions: {
task: string;
owner: string;
deadline: string;
}[];
attention_points: string[];
next_step: string;
}
Quel LLM choisir : API ou self-hosted ?
Nous avons quasiment terminé, il nous reste maintenant à choisir le LLM adéquat pour exécuter notre pipeline. L'objectif est de trouver la solution qui m'offrira le meilleur rapport qualité-prix.
Je lance une petite étude de marché avec Claude pour étudier les possibilités. J'avais d'abord pensé à faire tourner un LLM sur un VPS dédié au sein de mon architecture technique. Claude me recommande plutôt d'utiliser l'API Mistral avec le modèle Small.

On voit bien la différence de coûts entre les deux approches : une quarantaine d'euros par mois pour la version self-hosted, et quelques centimes seulement en passant par l'API Mistral. Le choix est fait, on peut passer à l'étape suivante.
Rédiger le prompt système pour Mistral
Nous allons maintenant expliquer au LLM ce que nous attendons de lui. Bien que j'aie rédigé un article sur les bonnes pratiques en matière de prompt engineering, je vais ici demander à Claude de rédiger le prompt système directement :
// ===== Build Mistral Payload =====
// Sortie : { body } → envoyé tel quel au node HTTP Request (Mistral).
// --- PROMPT (édite librement ici) ---
const SYSTEM_PROMPT = `Tu es un assistant d'extraction au service de David Moothen, fondateur de la société Jinious.
CONTEXTE
Ces comptes-rendus sont rédigés par David Moothen (Jinious), prestataire, pour garder une trace de ses échanges avec ses clients et prospects. David / Jinious est TOUJOURS le prestataire ; l'autre partie est le client ou le prospect. Ne considère jamais David Moothen ni Jinious comme le client. Rédige le summary et les autres textes de façon factuelle, du point de vue de Jinious (par exemple « Le client souhaite… », « Jinious doit envoyer… »).
À partir d'un compte-rendu rédigé ou dicté en français (souvent informel, parfois incomplet), tu produis UNIQUEMENT un objet JSON conforme au schéma imposé, sans aucun texte ni balise autour.
RÈGLES ABSOLUES
- N'invente jamais une information absente du message. Aucune supposition.
- Inclus TOUJOURS toutes les clés du schéma.
- Champ texte sans information disponible : valeur null.
- Liste sans élément disponible : tableau vide [].
- Action sans owner ou sans deadline : mets ces champs à null.
- Dates toujours au format AAAA-MM-JJ. Résous les dates relatives (hier, lundi, la semaine prochaine) à partir de la Date du jour fournie dans le message. Si aucune date n'est mentionnée, mets meeting_date à null (ne devine pas).
CHAMPS À PRODUIRE
- title : titre court au format RDV <client> - <sujet>. Si le sujet est inconnu, mets RDV <client>.
- client : nom du client ou prospect tel qu'il est mentionné, sans le normaliser. Jamais David Moothen ni Jinious.
- meeting_date : date de l'échange (AAAA-MM-JJ) ou null.
- participants : un élément par personne présente, rôle entre parenthèses si connu, par exemple Marie Dupont (DG). Inclure David Moothen (Jinious) s'il est partie prenante. Tableau vide si aucun participant identifiable.
- summary : synthèse de 2 à 5 phrases, du point de vue de Jinious, uniquement à partir de ce qui est dit.
- key_points : faits et chiffres marquants.
- decisions : décisions actées pendant l'échange.
- actions : chaque action est un objet avec task (la tâche), owner (qui la porte — David Moothen / Jinious ou côté client — ou null) et deadline (AAAA-MM-JJ si exprimée ou calculable, sinon null).
- attention_points : risques et points de vigilance.
- next_step : prochaine étape concrète, ou null.
- source : canal par lequel ce client/prospect est arrivé, UNIQUEMENT si mentionné, parmi : Mon réseau, Site, Blog, LinkedIn, Malt, Autre. Si non mentionné, null.
- recommandation : si le lead a été recommandé / apporté par une ou plusieurs personnes nommées, liste leurs noms. Sinon tableau vide.
Ne produis rien d'autre que l'objet JSON.`;
// --- SCHÉMA DE SORTIE (json_schema strict) ---
const RESPONSE_FORMAT = {
type: "json_schema",
json_schema: {
name: "client_meeting",
strict: true,
schema: {
type: "object",
additionalProperties: false,
properties: {
title: { type: "string" },
client: { type: "string" },
meeting_date: { type: ["string", "null"] },
participants: { type: "array", items: { type: "string" } },
summary: { type: ["string", "null"] },
key_points: { type: "array", items: { type: "string" } },
decisions: { type: "array", items: { type: "string" } },
actions: {
type: "array",
items: {
type: "object",
additionalProperties: false,
properties: {
task: { type: "string" },
owner: { type: ["string", "null"] },
deadline: { type: ["string", "null"] }
},
required: ["task", "owner", "deadline"]
}
},
attention_points: { type: "array", items: { type: "string" } },
next_step: { type: ["string", "null"] },
source: { type: ["string", "null"], enum: ["Mon réseau", "Site", "Blog", "LinkedIn", "Malt", "Autre", null] },
recommandation: { type: "array", items: { type: "string" } }
},
required: ["title","client","meeting_date","participants","summary","key_points","decisions","actions","attention_points","next_step","source","recommandation"]
}
}
};
// --- ENTRÉE TELEGRAM (adapte le chemin si besoin) ---
const messageText = $json.message?.text ?? "";
const today = $now.toFormat('yyyy-MM-dd');
// --- PAYLOAD MISTRAL ---
const body = {
model: "mistral-small-latest",
temperature: 0,
response_format: RESPONSE_FORMAT,
messages: [
{ role: "system", content: SYSTEM_PROMPT },
{ role: "user", content: `Date du jour : ${today}\n\nMessage :\n${messageText}` }
]
};
return { body };Comme le code est conséquent, je décide de l'isoler dans un node Code placé entre les nodes Telegram et LLM. Cela me permettra de debugger et faire évoluer le code plus facilement.
Générer les blocks Notion
Dernière étape pour terminer le pipeline : sauvegarder les données dans Notion. Contrairement à la version simplifiée, nous avons procédé à quelques changements :
- nous n'ajoutons plus du texte dans une page, mais des entrées dans une base de données
- nous avons aussi ajouté de nouveaux champs dans le retour du LLM qui n'apparaissent pas encore côté Notion
Pour ce faire, nous allons ajouter des blocks : chaque titre, paragraphe, bullet item, etc. constitue un block pour Notion. Nous allons donc pour chaque entrée ajouter une liste de blocks "Résumé", "Points-clés", et ainsi de suite.
Je demande à Claude de me fournir le code pour générer le payload et je l'isole dans un node dédié, comme nous l'avons fait pour le prompt du LLM. Je place ce node juste avant de faire la sauvegarde. Vous trouverez ci-dessous le code en question :
const data = JSON.parse($json.choices[0].message.content);
const databaseId = "xxx"; // À remplacer par ton ID
function createBulletBlock(text) {
return {
object: "block",
type: "bulleted_list_item",
bulleted_list_item: { rich_text: [{ type: "text", text: { content: text } }] }
};
}
function createHeadingBlock(text) {
return {
object: "block",
type: "heading_2",
heading_2: { rich_text: [{ type: "text", text: { content: text } }] }
};
}
function createParagraphBlock(text) {
return {
object: "block",
type: "paragraph",
paragraph: { rich_text: [{ type: "text", text: { content: text || "Non spécifié" } }] }
};
}
function createBulletedListItems(items) {
if (items.length === 0) {
return [createParagraphBlock("Non spécifié")];
}
return items.map(obj => createBulletBlock(obj));
}
// Construire les children (blocs du corps)
const children = [
createHeadingBlock("Summary"),
createParagraphBlock(data.summary),
createHeadingBlock("Key Points"),
...createBulletedListItems(data.key_points),
createHeadingBlock("Decisions"),
...createBulletedListItems(data.decisions),
createHeadingBlock("Actions"),
...createBulletedListItems(data.actions.map(a => `${a.task}${a.owner ? ' — ' + a.owner : ''}${a.deadline ? ' (deadline: ' + a.deadline + ')' : ''}`)),
createHeadingBlock("Attention Points"),
...createBulletedListItems(data.attention_points),
createHeadingBlock("Next Step"),
createParagraphBlock(data.next_step)
];
// Payload final pour l'API Notion
return {
parent: { database_id: databaseId },
properties: {
"Titre": {
title: [{ type: "text", text: { content: data.title } }]
},
"Source": {
select: { name: data.source || "Autre" }
},
"Client": {
rich_text: [{ type: "text", text: { content: data.client || "Non spécifié" } }]
},
"Date RDV": {
date: { start: data.meeting_date || $now.toFormat('yyyy-MM-dd') }
},
"Participants": {
multi_select: data.participants.map(p => ({ name: p.split(',').join(' -') }))
},
"Recommandation": {
multi_select: (data.recommandation || []).map(r => ({ name: r.split(',').join(' -') }))
},
"Prochaine étape": {
rich_text: [{ type: "text", text: { content: data.next_step || "Non spécifié" } }]
}
},
children: children
};
Appeler les API avec des nodes Http Request
Nous allons finaliser le pipeline, et pour cela nous allons procéder à une dernière correction. Plutôt que d'utiliser les nodes dédiés Mistral et Notion fournis par n8n, nous allons utiliser des Http Request. Autrement dit, nous allons appeler leur api respective directement.
Dans le cas de Notion, je ne peux pas créer une entrée et ajouter des blocks dans le même node avec l'api, je peux passer un payload avec toutes les informations et appeler le endpoint POST https://api.notion.com/v1/pages de l'api Notion.
L'idée est d'isoler le code de génération dans un node dédié juste avant le node Http Request, ce qui rend le pipeline plus compréhensible. J'applique également cette méthode pour utiliser Mistral.
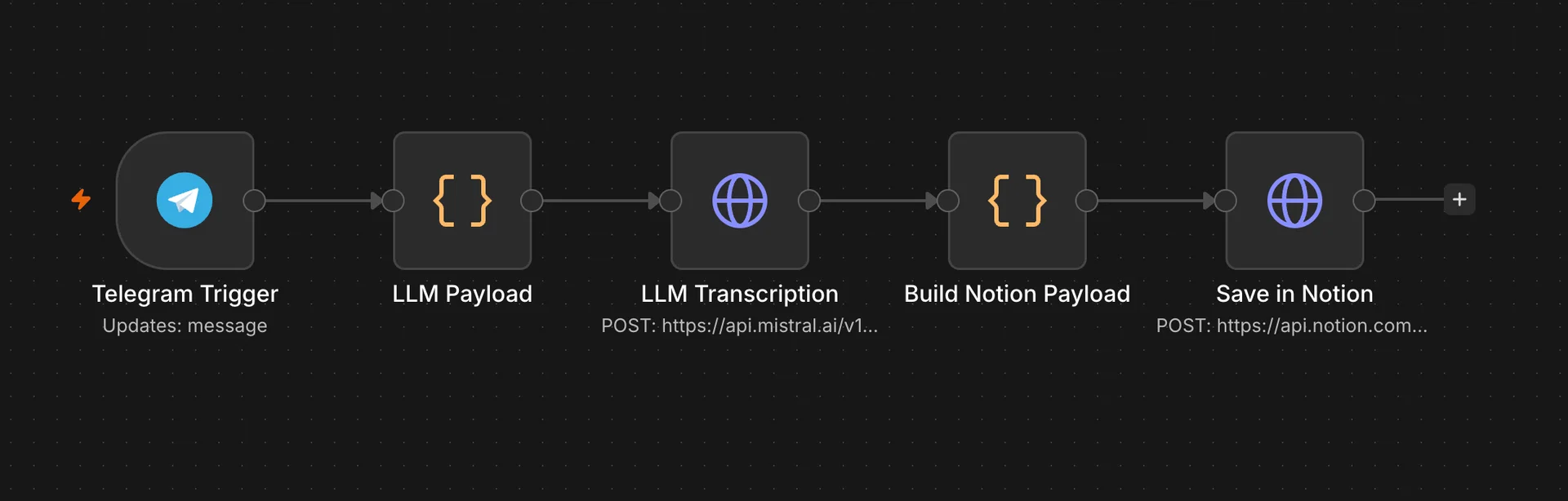
Le résultat : un pipeline en 5 nodes
Après avoir effectué ces quelques modifications, nous obtenons un pipeline fonctionnel composé de 5 nodes : 3 nodes pour capter, structurer et sauvegarder un compte rendu, et 2 nodes intermédiaires pour faire lien entre eux.
Voici notre pipeline finalisé :
Pour tester le pipeline, je demande à l'IA de me générer 10 messages pour créer des données tests avec le prompt suivant :
Tu es un expert en génération de cas d'étude commerciaux pour des consultants IT/développeurs. Tu dois générer 10 exemples de messages dictés à l'oral, comme des notes prises par un consultant après un appel ou un rendez-vous commercial.
CONTRAINTES: - Chaque message doit sonner naturel et conversationnel, comme quelqu'un qui dicte rapidement après un appel - Inclure des hésitations, des tournures de phrase informelles ("du coup", "franchement", "genre", "quoi") - Pas de mise en forme structurée (pas de tirets, pas de sections, juste du texte fluide) - Chaque message fait entre 150 et 300 mots - Les clients contactent pour des problématiques tech/développement/CTO (pas juste des sites vitrines)
CONTENU: - Inventer des noms de personnes, d'entreprises et de secteurs d'activité variés (au moins 8 secteurs différents) - Pour chaque exemple, inclure: * Nom et rôle de l'interlocuteur * Nom de l'entreprise * Contexte/problématique technique spécifique * Enjeux business liés * Prochaines étapes attendues - Les problématiques peuvent être: migrations cloud, intégrations, automatisation, performance, sécurité, modernisation de legacy code, BI/analytics, architecture, scalabilité, etc.
VARIATION: - Au moins 2 messages doivent concerner le MÊME client (suite de rendez-vous, évolution de la réflexion) - Chaque problématique doit être différente - Varier les tailles d'entreprises (startup, PME, petite structure)
STYLE: - Ton conversationnel, comme de l'oral capté - Utiliser "alors", "donc", "du coup", "franchement", "il m'a dit que", etc. - Pas de formulations trop structurées ou formelles
Génère ces 10 exemples maintenant.
Je récupère ensuite les messages générés que j'envoie un par un depuis Telegram.
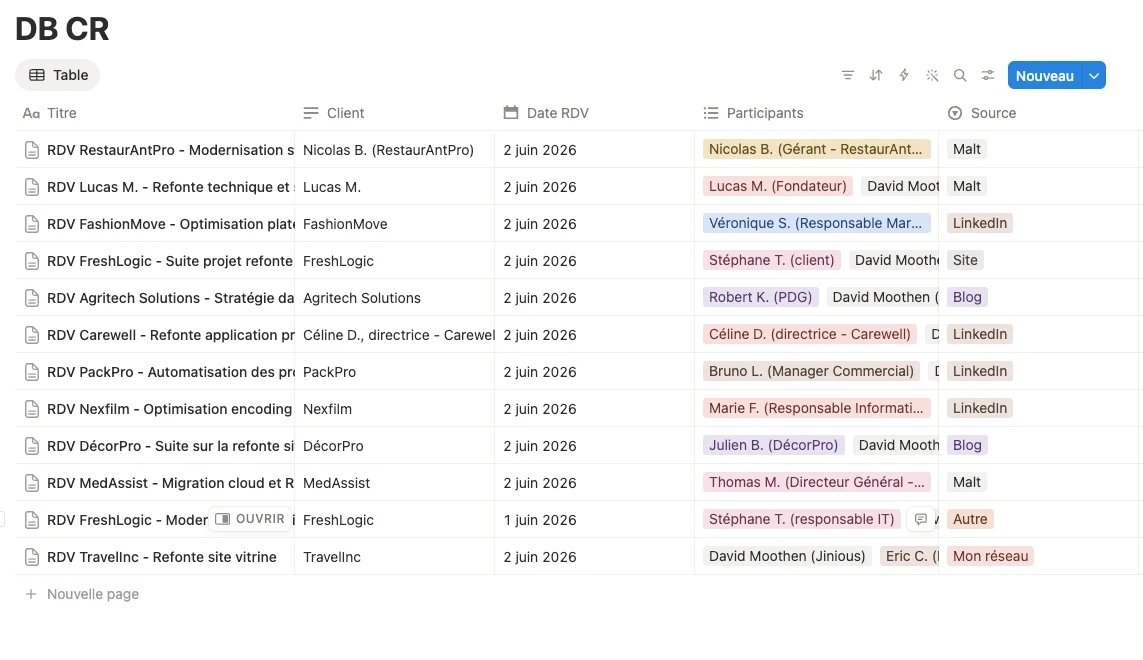
Et voici maintenant le résultat complet avec le compte rendu sauvegardé dans Notion :
Bilan : ce qui fonctionne et les limites
Il m'aura fallu quelques jours pour mettre cette automatisation en place. J'ai mieux compris le fonctionnement de n8n, comment construire un pipeline, choisir les bons nodes et les séquencer efficacement. J'ai aussi découvert Notion, que je n'avais jamais vraiment utilisé, et réalisé qu'on pouvait tout à fait s'en servir comme une base de données.
Au final, je dois avouer qu'à l'usage, ce pipeline est très pratique. Je termine un rendez-vous, je dicte mon compte rendu depuis mon téléphone, et quelques secondes plus tard il est structuré et rangé dans Notion, prêt à être consulté. Si j'étais parti sur le développement d'un CRM complet, j'aurais mis bien plus de temps à obtenir la même chose, rien que sur la partie base de données, Notion m'a fait gagner un temps précieux. La leçon de mon précédent article a porté ses fruits.
Par contre, tout n'est pas parfait. L'automatisation ne gère pas l'unicité des clients : chaque entrée est indépendante des autres, sans lien entre deux comptes rendus d'un même client. Je ne peux pas non plus joindre de pièces comme des devis, factures, captures d'écran etc. Je reviendrai sûrement dessus pour ajouter ces fonctionnalités, ce qui fera l'objet d'un second article.
Quoi qu'il en soit, j'ai maintenant une base solide pour gérer mes futurs rendez-vous clients. Et le plus intéressant, c'est que je commence à peine à entrevoir ce que ce genre d'automatisation peut m'apporter au quotidien.