Prompt engineering : 2 mois avec Claude, ce que j'ai appris
Développeur senior, j'ai passé 2 mois à prompter Claude au quotidien. Pièges concrets, méthode en 8 points et exemple réel pour écrire de meilleurs prompts.
- Les LLM produisent du texte plausible, sans garantie de véracité : ils peuvent se tromper avec aplomb (un calcul de dividende faux, une analyse de site erronée).
- 4 pièges à connaître : contexte qui se dégrade, knowledge cutoff, absence de recherche web par défaut, fausse assurance.
- Ma méthode de prompt en 8 points : donner du contexte, demander une recherche web sourcée, structurer la requête, jouer sur les modalités et le ton, définir le format de sortie, autoriser le « je ne sais pas », faire améliorer puis valider le prompt.
- Exemple concret : choisir une bibliothèque UI (shadcn/ui vs Chakra vs Radix) via un prompt scoré → décision en quelques minutes.
- À retenir : c'est à vous de mener la réflexion, l'IA n'est qu'un outil — entraînez-vous à la faire mentir pour aiguiser votre vigilance.
Cela fait maintenant deux mois que je teste Claude régulièrement, principalement dans le cadre professionnel et je voudrais vous faire part de mon retour d'expérience car la manière dont je communique avec lui a bien évolué.
En tant que développeur, la question pour moi n'est plus de savoir si je dois utiliser l'IA dans mes projets, mais plutôt comment l'utiliser ?
Mes premiers pas avec l'IA en tant que développeur
Je constate que mon métier tel que je l'ai exercé ces 15 dernières années est en train de profondément changer. L'IA est maintenant devenue capable d'écrire du code complet et fonctionnel, et cela a déjà un réel impact sur la manière de rechercher l'information et de concevoir une application aujourd'hui, comme le montre l'exemple qui suit.
Générer un CV en une demi-journée avec Claude Code
Cela faisait plusieurs années que je n'avais pas remis à jour mon CV. Je me suis dit que ça serait une tâche parfaite pour commencer à jouer avec l'IA. J'ai donc démarré une conversation avec Claude.
S'ensuit une série d'échanges dans laquelle il me demande un certain nombre d'informations. Je lui ai ensuite décrit mes expériences professionnelles une par une, et lui ai demandé de me les réécrire afin de les mettre en valeur. Au bout d'un gros quart d'heure, le texte était prêt. À ce stade, j'avais déjà évité plusieurs heures de prise de tête !
Je n'avais plus qu'à le mettre en page. Je trouve un design qui me plaît mais là, problème : je lance Word, mais mes compétences sont très limitées ! J'ai essayé pendant 10 minutes sans succès… J'ai réalisé à ce moment-là que ça serait beaucoup plus facile pour moi de coder une page web qui affiche mon CV. Et je me suis dit que cela serait un projet intéressant à développer pour tester les capacités de code de l'IA.
Je lance donc Claude Code, je lui donne le texte que j'ai préparé plus tôt, une image du template que je voulais répliquer et lui explique que je veux développer une page web qui affichera mon CV au format A4 que je n'aurai plus qu'à imprimer. J'affine le résultat étape par étape, en plusieurs prompts, jusqu'à obtenir le résultat escompté.
J'aurais pu m'arrêter là, mais je décide d'aller encore plus loin : le texte du CV est écrit en dur, donc impossible de modifier le CV sans modifier le code source. Je demande donc à Claude de modifier l'interface pour ajouter un grand formulaire sur la droite de l'écran permettant de "saisir" le texte de son CV, et de voir celui-ci prendre vie en temps réel.
J'ai donc réussi à créer un générateur de CV en une demi-journée. Pas mal !
Ce que cette expérience m'a appris
Première expérience on ne peut plus concluante. Le projet n'est pas forcément très complexe à réaliser, mais si j'avais dû écrire le code manuellement, cela m'aurait pris au moins 2 jours.
Le générateur est accessible gratuitement ici si vous voulez y jeter un coup d'œil, et vous êtes libre de vous en servir si vous en avez besoin.
Quand l'IA se trompe : 2 anecdotes qui m'ont fait douter
Mais comme nous allons le voir, j'ai aussi eu quelques déconvenues. Voici une anecdote qui m'a particulièrement marquée, car la tâche en elle-même était plutôt simple et pourtant le résultat va être étonnant !
Le calcul de dividende faux (et confiant)
J'ai demandé à l'IA de déterminer la valeur brute des dividendes que je souhaitais me verser à partir du montant net désiré. Il existe de nombreux simulateurs en ligne pour vérifier son calcul.
Le calcul en lui-même est correct, mais il y a un détail dans sa réponse qui m'interpelle :

J'ai remis en cause sa réponse car je savais que le taux allait augmenter. Mais ce qui est particulièrement frappant ici, ce n'est pas seulement que l'IA se trompe. Elle disqualifie activement la bonne réponse ! Je confirme quand même mes dires sur le site des impôts avant de le questionner. Voici sa réponse :

Pas plus d'explications ! Je creuse davantage :

L'analyse de site erronée
Autre cas relativement intéressant : je venais de finir de développer la première version du site Internet de ma société, Jinious. Je demande cette fois à Gemini de consulter le site et de me dire ce qu'il en comprend. Je voulais aussi bien tester les capacités d'analyse d'une IA que vérifier la façon dont le site serait perçu.
Pour lui, je suis un logiciel qui s'appelle Jinio et qui est "Business Operating System ou Ops Platform" !
Je lui demande s'il a bien lu le site en faisant un fetch. Il me confirme que oui et qu'il a bien "lu" les différentes sections de la page d'accueil et des pages secondaires accessibles (il n'y a qu'une seule page sur le site) et en particulier le texte et les mots-clés, la structure des fonctionnalités et l'interface visuelle.
Je dois lui envoyer un screenshot du site pour qu'il corrige le tir : Jinio n'est pas une plateforme logicielle (SaaS), mais le site personnel d'un consultant/expert (Personal Branding).
À ce moment-là, je comprends que l'IA, bien que très puissante, peut se tromper. Et en particulier sur des tâches relativement simples. Cet exemple, en plus d'autres déconvenues, me fait remettre en cause tous les échanges que j'ai pu avoir avec lui depuis que je l'utilise. Je décide d'en savoir plus sur son fonctionnement.
Comprendre pourquoi : comment fonctionne un LLM ?
Je ne vais pas faire un cours complet sur le sujet, il y a plein de ressources très utiles qui expliquent beaucoup les concepts, et ce n'est pas l'objet de cet article. Je vais donc donner les éléments essentiels à comprendre.
Qu'est-ce qu'un Large Language Model
ChatGPT, Gemini, Claude et bien d'autres fonctionnent grâce au LLM.
C'est une branche de l'Intelligence Artificielle qui se concentre sur la compréhension, la prédiction et la génération de texte dans un langage naturel. L'objectif est de pouvoir générer une suite de mots syntaxiquement correcte et qui fait sens sémantiquement, comme un être humain pourrait l'écrire.
Il a été entraîné sur une vaste quantité de textes, ce qui lui permet dans une suite de mots de prévoir les mots suivants.
Pourquoi un LLM peut "mentir" sans s'en rendre compte
Et c'est bien ça qu'il faut avoir en tête. L'objectif est de générer du texte qui semble naturel et cohérent. Pour autant, rien ne garantit la véracité de ce qui est dit.
On le voit bien dans mon exemple précédent. Aucun problème avec la forme de la réponse, par contre la réponse en elle-même est fausse. Mais elle est tellement bien écrite qu'elle donne l'illusion d'être vraie.
Je mets ici quelques articles qui vont plus loin sur le sujet :
https://medium.com/data-science-at-microsoft/how-large-language-models-work-91c362f5b78f
https://www.data-bird.co/blog/llm-definition
https://www.sfeir.dev/llm-vs-modele-fondation-quelles-differences-dans-lunivers-de-lia-generative/
Les 4 pièges à connaître avant de prompter
Malgré le progrès technologique qu'elle représente, on voit que le piège numéro un du LLM réside dans sa conception même. Au cours de mon utilisation, j'ai aussi remarqué d'autres points d'attention. À noter qu'il s'agit d'une liste non exhaustive basée sur ma propre expérience, il y a probablement d'autres cas que je n'ai pas encore relevés. Je mettrai à jour cet article au fur et à mesure de mes progrès.
Le contexte qui se dégrade
Le LLM garde en mémoire les échanges dans une même conversation pour pouvoir s'en resservir dans ses prochaines réponses. C'est ce qu'on appelle le contexte. Lorsque ce contexte devient trop grand, la qualité et la rapidité des réponses commencent à décliner. Les LLM gèrent de mieux en mieux ce problème mais il faut savoir qu'il existe.
Pour en savoir plus sur le contexte : https://blog.logrocket.com/llm-context-problem-strategies-2026
La date de connaissance (knowledge cutoff)
Demandez à votre IA favorite quelle est sa date de connaissance, vous serez probablement surpris de sa réponse.
Pour rappel, les modèles sont entraînés sur un ensemble fini de données qui s'arrêtent à un instant T. Tout ce qui a eu lieu après ce moment lui est inconnu ! J'ai découvert ce point en lui demandant de générer des articles pour un blog. Ils étaient tous datés d'août 2025. Je lui ai donc posé la question pour en savoir plus.
NB : je précise que je n'ai pas gardé les articles en question car je les trouvais trop génériques, le présent article est intégralement écrit par mes soins.
L'absence de recherche web par défaut
Si votre requête ne demande pas explicitement ou implicitement à rechercher sur le web les dernières informations, le LLM ne le fera pas et se contentera de raisonner sur les connaissances qu'il a acquises lors de son entraînement. Il peut donc raisonner sur des données périmées.
Une amie m'a fait part d'une anecdote à ce sujet : elle a posé une question à Copilot qui lui a donné une réponse fausse car la législation avait changé. Elle le savait, mais pas Copilot, à cause de sa date de connaissance.
Avoir réponse à tout et avec assurance
On a déjà abordé ce point précédemment, un LLM est conçu pour fabriquer des phrases cohérentes dans un langage naturel et c'est exactement ce qu'il fait. Cela ne garantit pas qu'il nous donne une réponse exacte. Pire, comme vu précédemment il peut dans certains cas faire de lui-même des arbitrages sans nous en informer et fabriquer une réponse de toute pièce en faisant preuve d'autorité.
Encore une fois, c'est une liste basée sur mon expérience, il y a probablement d'autres biais dont il faut avoir connaissance.
Comment écrire des prompts efficaces : ma méthode en 8 points
Maintenant qu'on a bien joué avec l'IA et qu'on a pu se faire une première idée de son fonctionnement, comment faire pour l'utiliser efficacement ? Il est temps de voir comment nous pouvons adresser nos requêtes de manière pertinente et obtenir des réponses efficaces.
Donnez-lui un maximum de contexte
Ne vous contentez pas d'une simple question d'une ligne. Plus le LLM en sait sur vous et la raison de votre question, plus il pourra vous donner des réponses pertinentes. À l'inverse, moins vous donnez d'informations, plus les réponses que vous obtiendrez seront génériques.
Demandez-lui de faire une recherche sur le web
On l'a vu précédemment, le LLM ne fait pas nécessairement de recherche pour produire un résultat à partir de données à jour. Dans le même ordre d'idées, il est fort intéressant de lui expliciter un certain nombre de choses, en particulier de privilégier et comparer des sources fiables, et de les citer (dans mon exemple sur les dividendes, l'erreur était due au fait qu'il est allé consulter une source moins fiable que la source officielle).
Organisez votre requête
Si votre requête nécessite plusieurs étapes pour obtenir une réponse, ou que vous posez plusieurs questions dans une seule demande, vous risquez d'impacter la qualité de la réponse. Dans ce cas, privilégiez une structure qui lui permettra d'organiser sa pensée, étape par étape. Il pourra ainsi utiliser ses propres réponses pour continuer sa réflexion. Vous pouvez utiliser des mots-clés comme : commence par, dans un premier temps, ensuite, dans un second temps, enfin, termine par, etc.
Jouez sur les modalités
Personnellement, j'aime faire de la veille concurrentielle, c'est même essentiel dans mon métier. Quand je trouve une technologie qui m'intéresse, avant je lui demandais de faire une liste des points forts et des points faibles, ce qui donne une réponse assez générique et pas forcément intéressante. Par contre, si je lui demande de me citer les 3 points forts et les 3 points faibles de la technologie, là j'ai un résultat plus précis et concret.
Je peux aussi aller plus loin en lui demandant de me faire cette analyse d'un point de vue précis. Dans mon cas, cibler une communauté de développeurs, et même préciser quelles communautés je veux cibler (slack, discord, reddit, etc.) me donnera un résumé des avis de personnes qui ont un profil similaire au mien, et donc un retour encore plus qualifié.
Vous pouvez aussi jouer sur le ton de la réponse. Vous êtes expert dans un domaine, dites-le lui et demandez-lui de répondre de la même manière. Vous êtes novice sur un sujet, ou vous souhaitez vous former sur une compétence, demandez-lui de vous répondre comme un professeur enseigne à ses étudiants, de manière pédagogique.
Ce ne sont que quelques exemples, mais vous voyez l'idée.
Définissez le format de la réponse
Ce n'est pas forcément obligatoire, mais cela peut être utile dans certains cas. Par exemple, lorsque l'on demande une analyse ou une comparaison, demander à afficher les résultats sous forme de tableau trié par ordre de pertinence sera plus efficace qu'un simple retour de texte dans le chat. On peut même aller plus loin en définissant nous-même le critère de pertinence. Ce que j'aime bien faire dans le cas d'une analyse comparative, c'est définir un score : sur 5, sur 10, un pourcentage ? sur quels critères ?
Autorisez-le à dire "je ne sais pas"
C'est étrange comme recommandation et pourtant ça peut faire une grande différence. Les LLM sont programmés pour donner une réponse. Le risque, c'est qu'il invente une réponse sans nous le préciser. Et on l'a vu plus haut, dans ce cas la réponse semble véridique. Avec ce garde-fou, la réponse sera nettement plus neutre et le LLM indiquera clairement quand il n'a pas trouvé les informations dont il avait besoin ou qu'il émet des hypothèses.
Demandez à l'IA comment améliorer le prompt
Encore une fois, cela peut paraître paradoxal, mais qui de mieux que l'IA elle-même pour vous expliquer comment elle fonctionne ? Je fais régulièrement cet exercice, c'est d'ailleurs comme ça que j'ai commencé à optimiser mes prompts. J'ai d'ailleurs été très surpris de la qualité de ses réponses. Encore une fois, tout dépend de la manière dont vous allez lui adresser votre demande.
Demandez-lui de vous poser des questions
En faisant cela, vous vous assurez que votre demande a été bien comprise, et vous pouvez recalibrer si vous voyez qu'il y a un souci d'interprétation ou si vous avez besoin de compléter votre prompt.
Demandez-lui d'afficher le prompt optimisé et d'attendre votre validation
Dernier point de contrôle avant d'exécuter le prompt. Le fait d'afficher le prompt vous permettra aussi de vous rendre compte de la différence entre la demande initiale et la version optimisée.
Exemple concret : comment j'ai choisi entre Chakra UI, Radix et Shadcn
Je vais vous partager un exemple concret d'application. Je voulais utiliser une bibliothèque de composants UI dans le développement de mes futurs projets et j'avais déjà présélectionné 3 candidats : ChakraUI, Radix et Shadcn. En appliquant ces concepts, voici le prompt optimisé :
Rôle
Tu es un développeur senior avec plus de 20 ans d'expérience dans le développement web. Tu as vécu les évolutions techniques du PHP/MySQL aux frameworks JavaScript modernes (Angular, Vue, React). Tu t'es spécialisé ces 8 dernières années sur la stack Next.js / NestJS / PostgreSQL et tu enseignes à de jeunes développeurs comment construire des applications web robustes. Ton style est direct, pragmatique, et tu illustres par des exemples concrets issus de ton expérience terrain.
Contexte du projet (à utiliser comme grille de lecture pour TOUTE l'analyse)
Je construis un boilerplate Next.js réutilisable destiné à plusieurs typologies de projets futurs : landing pages, blogs, et applications SaaS. Mes contraintes techniques :
- Next.js 15 avec App Router et React Server Components par défaut
- Tailwind CSS v4 déjà configuré
- TypeScript strict
- Priorité forte sur : vélocité de mise en route, cohérence visuelle entre projets, maintenabilité long terme, et contrôle visuel total (je suis freelance Fractional CTO, le boilerplate doit pouvoir s'adapter à chaque client sans dette technique)
- Public cible secondaire : juniors qui pourraient reprendre le code, donc la courbe d'apprentissage compte
Mission de recherche
Effectue une recherche web rigoureuse pour analyser 3 solutions : shadcn/ui, Chakra UI, et Radix (traite séparément Radix UI Primitives — composants headless — et Radix Themes — système de design stylé, car ce sont deux couches d'abstraction différentes).
Exigences de sourcing :
- Minimum 5 sources récentes (< 6 mois si possible)
- Priorise dans cet ordre : docs officielles, retours d'expérience sur Reddit (r/nextjs, r/reactjs), Hacker News, dev.to, blogs techniques de référence, benchmarks GitHub (étoiles, issues actives, fréquence des releases)
- Mentionne explicitement la date de publication des sources clés
- Vérifie la compatibilité réelle (pas marketing) avec Tailwind v4 et React Server Components — c'est un point qui évolue vite
Réponds aux questions dans l'ordre :
1. À quelle famille de framework / librairie appartient chacun de ces projets ? (composants stylés, headless, design system complet, copy-paste, etc.)
2. Pour chacun, présente sous forme de tableau comparatif :
- 3 points forts remontés par la communauté
- 3 points faibles remontés par la communauté
- Facilité de customisation (note /5 + justification)
- Compatibilité avec une config Tailwind v4 existante (oui/non/partielle + détails)
- Compatibilité React Server Components (oui/non/partielle + détails)
3. Recommandation finale tranchée : vaut-il mieux adopter l'une de ces solutions ou continuer à construire mes propres composants pour mon boilerplate ?
Note chaque option (incluant "build my own") sur une grille de 5 critères pondérés :
- Vélocité de mise en route (poids 25%)
- Contrôle visuel et personnalisation (poids 25%)
- Maintenabilité long terme (poids 20%)
- Compatibilité RSC + Tailwind v4 (poids 20%)
- Courbe d'apprentissage pour un dev junior (poids 10%)
Termine par une recommandation argumentée en 3-5 phrases, en tenant compte de mon contexte freelance et de la diversité de mes projets cibles.
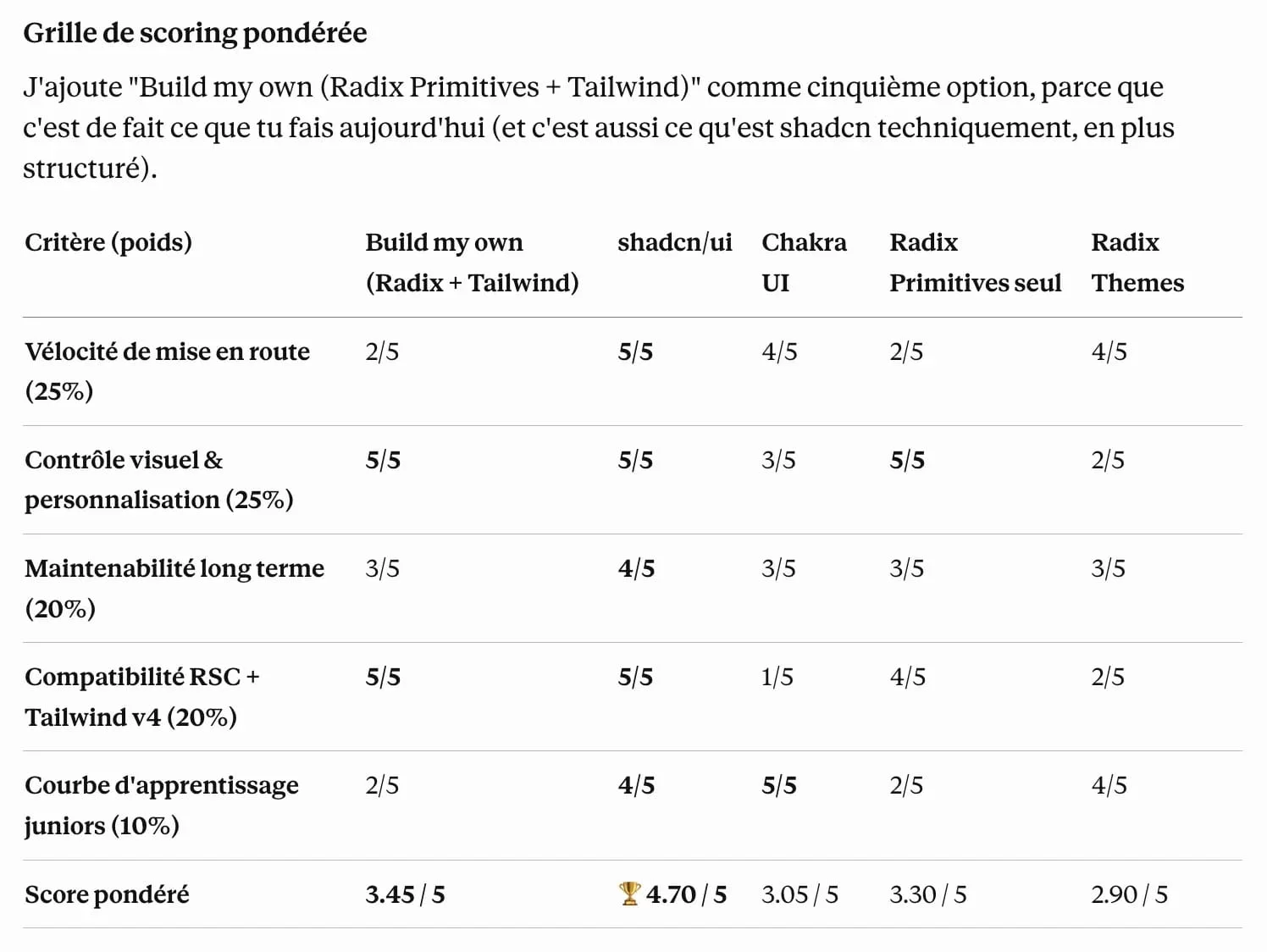
Et voici maintenant le tableau de scoring pondéré comparant Build my own (Radix + Tailwind), shadcn/ui, Chakra UI, Radix Primitives seul et Radix Themes. shadcn/ui obtient le meilleur score pondéré de 4,70 sur 5.
Cela peut paraître démesuré étant donné la requête, et c'est peut-être le cas. Cela dépend du degré de précision recherché. L'exemple que je cite pour moi est une question importante car une mauvaise décision peut remettre en cause des jours de développement ! Cette réponse m'a permis de prendre une décision en quelques minutes.
Astuce : Il est possible de grandement simplifier ce travail en apprenant à maîtriser son LLM, il est possible d'utiliser sa mémoire pour sauvegarder des informations de contexte ou des éléments récurrents de prompts. Cela vous permettra de gagner en rapidité.
Ce qu'il faut retenir pour bien prompter
L'IA et les LLM sont des outils incroyables qui, bien utilisés, peuvent vraiment nous faire gagner du temps, optimiser nos performances et notre production. Et cela passe selon moi par la compréhension de son fonctionnement et la qualité des prompts qu'on lui adresse (prompt engineering).
L'IA peut mentir
On l'a vu plus haut, quand le LLM ne trouve pas de réponse, il peut en inventer une et paraître très fiable dans son retour. Pour vraiment en prendre conscience, j'ai un conseil qui peut sembler étrange mais je trouve que c'est très efficace : faites mentir l'IA ! Pas une ou deux fois par accident, mais régulièrement ! Plus vous le prenez la main dans le sac, plus vous augmentez votre vigilance.
Vous devez mener la réflexion, pas l'IA
Si vous lui demandez son avis sur un sujet ou sur un problème, vous déléguez le travail de réflexion. Le danger, c'est qu'il est possible que la réponse ne soit pas fiable ni même véridique, mais que vous la preniez pour acquise. Autrement dit, c'est à vous de réfléchir, pas l'IA. Si vous guidez correctement l'IA dans son travail d'analyse et de restitution, elle peut vous faire gagner un temps incroyable. C'est d'ailleurs de cette manière que j'ai automatisé la publication du blog.
C'est à vous de mener la réflexion, l'IA est un outil pour vous y aider.
Tout votre raisonnement doit être construit en ayant ce principe en tête. Si vous lui demandez de réfléchir à votre place, alors vous passez à côté de l'essentiel.
C'est ce qui fera selon moi la différence entre les personnes qui parviendront à surfer sur la vague de l'IA, et celles qui se feront emporter par elle.